数学界的AlphaGo时刻:谷歌DeepMindAI19秒解IMO几何题,仅差1分即可摘金牌
IMO被视为衡量人工智能系统高级数学推理能力的标杆,而谷歌DeepMind是第一个以银牌级别解决国际数学奥林匹克问题的人工智能。
高级数学推理是现代人工智能的关键能力。今天,Google宣布了一项长期重大挑战中的一个重要里程碑:Google混合人工智能系统在今年的国际数学奥林匹克竞赛(IMO)中获得了相当于银牌的成绩
具体来说google展示了第一个以银牌级别解决国际数学奥林匹克问题的人工智能
它结合了 AlphaProof(一种新的突破性形式推理模型)和 AlphaGeometry 2(之前系统的改进版本)
国际数学奥林匹克竞赛是全球最悠久、规模最大、最具声望的青年数学家比赛,自1959年起每年举办一次。参赛者需要解决六道涉及代数、组合学、几何和数论的极其困难的问题。许多菲尔兹奖得主曾在青年时期代表国家参加过IMO。近年来,IMO也成为了机器学习领域的一个重要挑战,被视为衡量人工智能系统高级数学推理能力的标杆
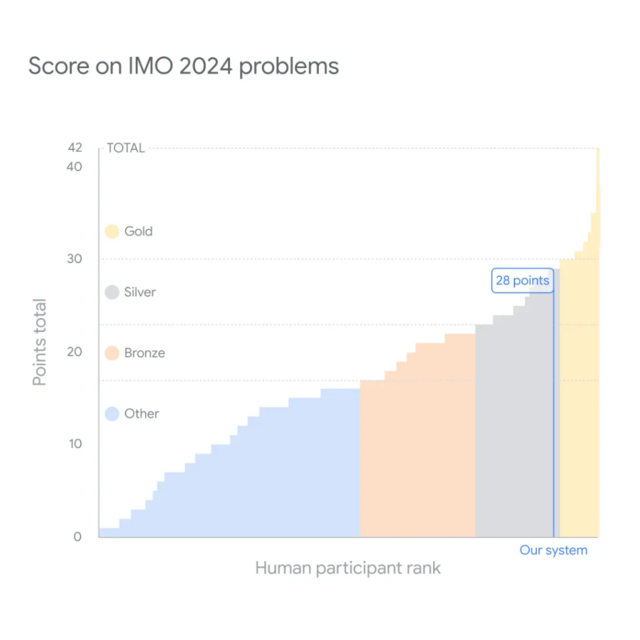
在今年的比赛中,DeepMind的AI系统获得了28分(满分42分),相当于银牌获得者的水平。这一成绩仅差1分就能达到金牌标准,而在今年的609名参赛者中,只有58人获得了金牌
AlphaProof:形式化数学推理的突破
AlphaProof系统采用强化学习方法,将预训练的语言模型与AlphaZero算法相结合。这种方法的优势在于可以正式验证涉及数学推理的证明的正确性。为了克服形式化语言训练数据不足的问题,研究团队通过微调Gemini模型,创建了一个包含各种难度的形式化问题库
AlphaProof是一个自学习系统,专门用于在形式化数学语言Lean中证明数学陈述。它的核心创新在于结合了预训练语言模型和AlphaZero强化学习算法
工作流程如下:
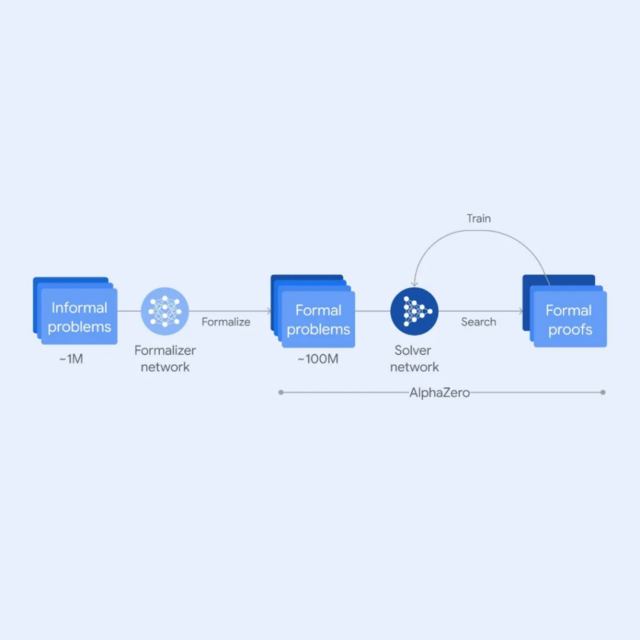
1.问题转化:首先,使用经过微调的Gemini模型将自然语言的数学问题自动转换为Lean的形式化语言。这一步骤创建了一个大型的形式化问题库,涵盖不同难度级别
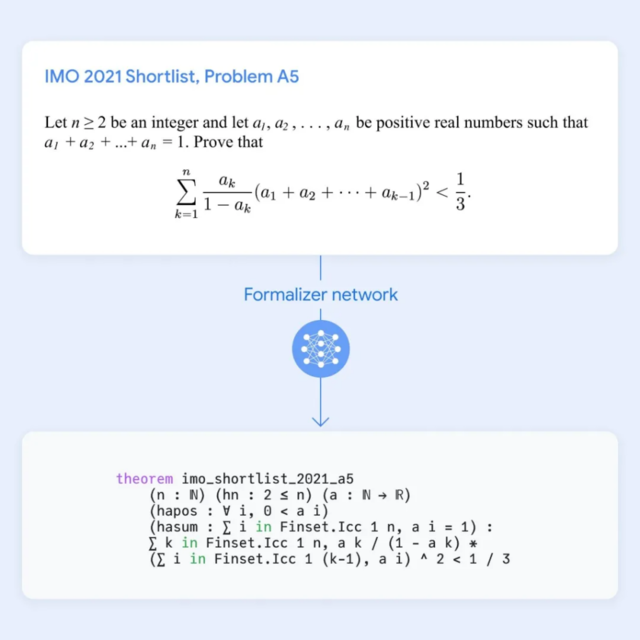
2.解决方案生成:面对一个新问题时,AlphaProof会生成可能的解决方案
3.证明搜索:系统在Lean中搜索可能的证明步骤,试图证明或反驳这些解决方案
4.强化学习:每找到并验证一个证明,就用它来强化AlphaProof的语言模型,提高系统解决后续更具挑战性问题的能力
5.持续训练:在准备IMO比赛期间,AlphaProof在数周内证明或反驳了数百万个问题,覆盖各种难度和数学主题。在比赛过程中,它还继续应用这个训练循环,通过证明自己生成的比赛问题变体来增强能力,直到找到完整解决方案
AlphaGeometry 2
AlphaGeometry 2是AlphaGeometry的改进版本,它的语言模型基于Gemini,并在比前代多一个数量级的合成数据上进行了训练
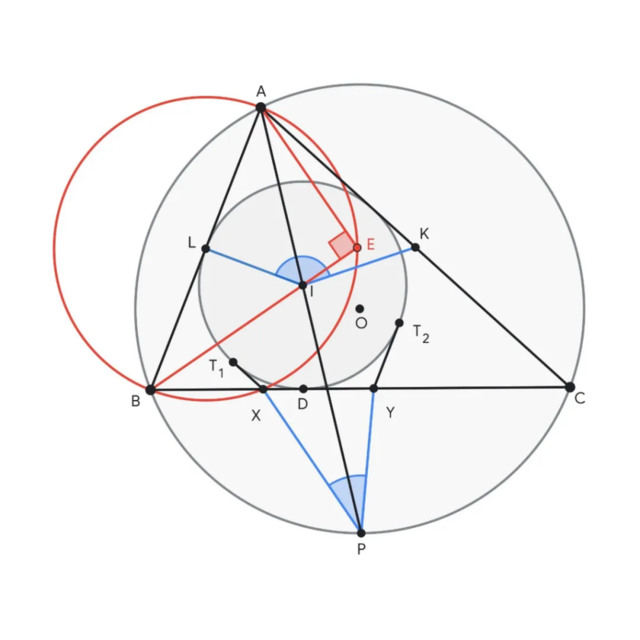
AlphaGeometry 2是一个神经符号混合系统。主要改进包括:
1.增强的语言模型:基于Gemini,从头开始训练,使用了比前代多一个数量级的合成数据。这大大提高了模型处理复杂几何问题的能力,包括物体运动、角度方程、比例或距离等问题
2.更快的符号引擎:新版本的符号处理引擎速度提高了两个数量级,大大加快了问题解决速度
3.知识共享机制:引入了新的知识共享机制,能够高级组合不同的搜索树,以解决更复杂的问题
4.性能提升:在接受今年IMO比赛前,AlphaGeometry 2能够解决过去25年IMO几何问题的83%,远超前代系统53%的解决率
5.实时表现:在今年的IMO中,AlphaGeometry 2在接收到形式化的第4题后,仅用19秒就解决了这个问题
6.DeepMind的研究团队还在探索基于自然语言推理的系统,这种系统不需要将问题转换为形式化语言,可能与其他AI系统结合使用。这种方法在今年的IMO问题上也显示出了巨大的潜力
本文作者:AI寒武纪,AI寒武纪,原文标题:《数学界的AlphaGo时刻:谷歌DeepMind AI 19秒解 IMO几何题,仅差1分即可摘金牌》
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。